
DevOps Processes: A Complete Guide for Enterprise & Mission-Critical Systems
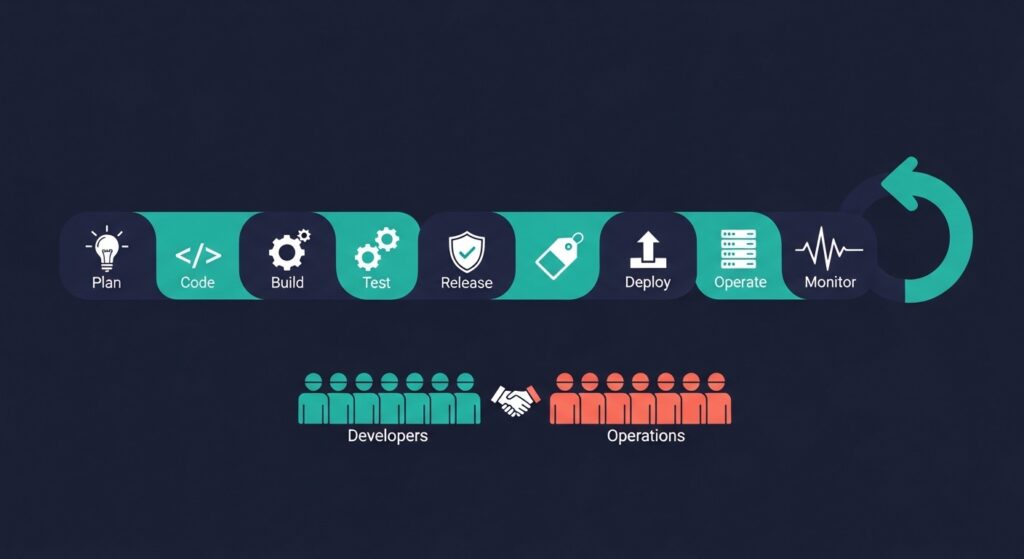
DevOps processes are the workflows, practices, and automation frameworks that unite software development and IT operations into a single, continuous discipline. The goal is not simply to ship software faster — it is to ship it faster without sacrificing stability, quality, or control. In enterprise and mission-critical environments, where the cost of failure is measured in five- and six-figure hourly downtime events, that balance is everything.
This guide covers the full DevOps lifecycle, the core components that make modern pipelines work, and the often-overlooked governance challenges that determine whether a DevOps process actually delivers on its promises in production.
What Are DevOps Processes?
DevOps processes are the structured set of practices that govern how software and configuration changes move from idea to production — and how that production environment is monitored, maintained, and improved over time. They sit at the intersection of development velocity and operational reliability, combining agile development methodologies with continuous integration, delivery, and deployment automation.
At its core, a DevOps process is defined by three characteristics: collaboration between development and operations teams who historically worked in silos; automation of repetitive, error-prone manual tasks across the build, test, and deployment pipeline; and continuous feedback that feeds real-world performance data back into the planning and development cycle.
When DevOps processes work well, organizations deploy more frequently, recover from failures faster, and maintain higher service levels than teams operating with traditional waterfall or siloed release models. When they break down — usually at the point where automation ends and manual intervention begins — the consequences in high-availability environments can be severe.
The DevOps Lifecycle Explained
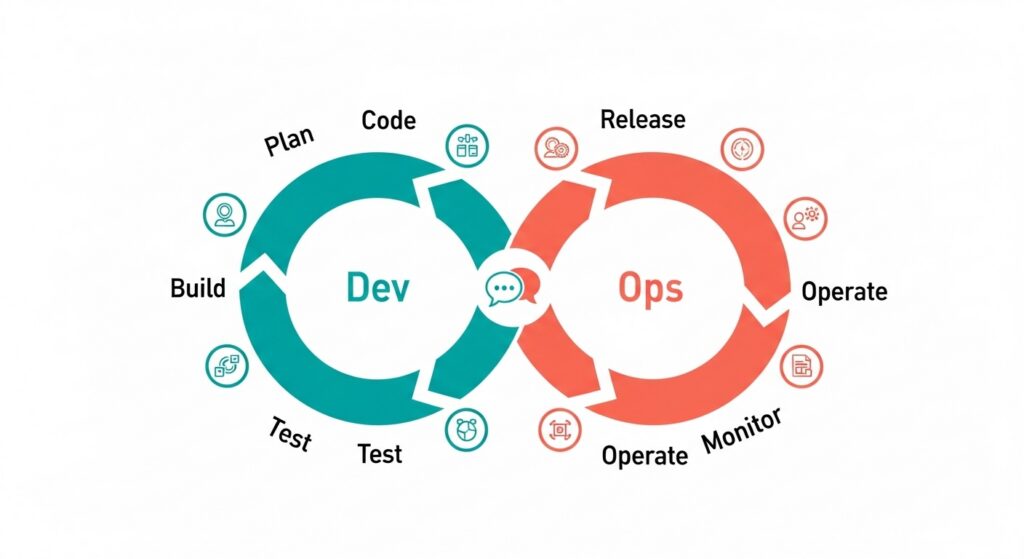
The DevOps lifecycle is typically represented as a continuous loop of eight phases. Understanding each phase is essential to understanding where processes succeed, where they introduce risk, and where automation adds the most value.
Plan
The lifecycle begins with planning. Teams define features, bug fixes, and infrastructure changes using agile methodologies — sprint cycles, backlog grooming, and stakeholder alignment sessions. In a mature DevOps process, planning is not a one-time upfront exercise but an ongoing cadence that keeps development aligned with business priorities and operational constraints. Poorly planned changes at this stage propagate downstream through every subsequent phase.
Code
Once a change is defined, developers write code in feature branches within a version control system — typically Git. Branching strategies (such as GitFlow or trunk-based development) determine how concurrent work streams are managed and how conflicts are resolved before integration. Version control is not just a development convenience; in enterprise DevOps, it is the foundation of auditability and rollback capability.
Build
The build phase transforms source code into deployable artifacts through automated build systems and CI servers. Dependency management, compilation, and packaging happen here. Continuous integration (CI) pipelines trigger a new build automatically with every code commit, ensuring that integration issues are surfaced immediately rather than accumulating silently across long development cycles.
Test
Automated testing runs against every build — unit tests, integration tests, security scans, and performance benchmarks. The DevOps principle of shift-left testing means quality checks are applied as early as possible in the pipeline, when defects are cheapest to fix. Continuous testing does not replace human judgment, but it dramatically reduces the volume of defects that reach later, more expensive stages of the pipeline.
Release
The release phase manages the transition from a validated build to a candidate ready for production deployment. It includes version tagging, change validation, release notes generation, and — in governed environments — formal change approval workflows. This is the phase where DevOps and change management intersect most directly, and where inadequate governance most frequently introduces risk.
Deploy
Deployment automation moves validated release candidates into production environments. Modern deployment strategies such as blue/green deployments (maintaining two identical environments and switching traffic between them) and canary releases (gradually routing a small percentage of traffic to the new version) reduce deployment risk by enabling fast rollback if issues emerge. Continuous deployment, at its most mature, means every validated build is deployed to production automatically — with human approval gates applied selectively based on risk level.
Operate
Once deployed, systems require active operational management. Infrastructure management, capacity monitoring, incident response, and high-availability configuration all fall within this phase. In complex enterprise environments, the operate phase often involves managing configuration across multiple interconnected systems — where a single misconfigured parameter can cascade into a broader service failure.
Monitor
Continuous monitoring captures performance telemetry, error rates, user behavior, and infrastructure health from the live production environment. Observability — the ability to understand internal system state from external outputs — is increasingly central to modern DevOps. The monitoring phase closes the feedback loop, surfacing the real-world signal that informs the next planning cycle and keeps the DevOps process genuinely continuous.
Core Components of Modern DevOps Processes
Continuous Integration (CI)
Continuous integration is the practice of merging developer code changes into a shared repository frequently — typically multiple times per day — with each merge triggering an automated build and test sequence. CI pipelines catch integration defects early, enforce code quality standards, and reduce the risk of large, complex merges that are difficult to validate and even harder to roll back. Jenkins, GitHub Actions, and GitLab CI are among the most widely used CI platforms in enterprise environments.
Continuous Delivery & Continuous Deployment
Continuous delivery (CD) ensures that every validated build is always in a deployable state — ready to be released to production on demand, with a single automated or human-triggered action. Continuous deployment takes this a step further, automatically releasing every validated build to production without manual intervention. The distinction matters in practice: most enterprises operate continuous delivery rather than continuous deployment, preserving human approval gates for high-risk or compliance-sensitive changes while automating everything else.
Infrastructure as Code (IaC)
Infrastructure as Code treats environment configuration — servers, networks, routing rules, access controls — as version-controlled code rather than manually maintained state. Tools like Terraform, Ansible, and AWS CloudFormation define infrastructure declaratively, making environments reproducible, auditable, and recoverable. In contact center and CX platform environments, IaC principles apply not just to cloud infrastructure but to platform configuration: routing logic, IVR flows, agent skill assignments, and queue parameters are all forms of configuration that benefit from the same version control and automated promotion discipline applied to application code.
Automation & Continuous Feedback
The connective tissue of a mature DevOps process is automation — eliminating manual touchpoints that introduce delay, inconsistency, and human error. Continuous feedback loops, driven by monitoring and observability data, ensure that the lessons of production are systematically fed back into planning and development. Without automation and feedback, DevOps degrades into a faster version of the same siloed, manual processes it was designed to replace.
DevOps Process Flow: How It All Connects
The DevOps process flow is not a linear sequence — it is an infinite loop. Changes flow from Plan through Code, Build, Test, Release, and Deploy into production, where they are Operated and Monitored, and where performance data feeds back into the next planning cycle.
The pipeline concept reflects this: every phase hands off to the next through automated triggers and validation gates, with no manual hand-transcription of state between stages. The architecture view of a mature DevOps pipeline looks like a series of automated checkpoints — each one either advancing a change toward production or failing it back to the appropriate earlier stage for remediation.
What makes this flow powerful in enterprise environments is not the speed of any individual phase, but the integrity of the handoffs between phases. A plan that does not propagate cleanly into the code phase, a build that is not reproducibly testable, a release that requires manual documentation, or a deployment that bypasses automation in favor of a direct production edit — each of these breaks the loop and reintroduces the risk that DevOps exists to eliminate.
DevOps Processes in Enterprise & Mission-Critical Environment
In consumer software, a failed deployment might briefly inconvenience users before being rolled back. In enterprise and mission-critical environments — contact centers, financial trading systems, healthcare platforms, regulated SaaS — the same failure can trigger contractual SLA penalties, regulatory scrutiny, and downtime costs that accumulate at thousands of dollars per minute.
This changes the calculus of DevOps significantly. Speed remains important, but it is subordinate to reliability, auditability, and recoverability. Enterprise DevOps processes must accommodate formal change approval workflows, comprehensive audit trails, compliance requirements, and rollback capabilities that standard DevOps toolchains were not originally designed to provide out of the box.
Contact centers are a particularly high-stakes example. They run on interconnected platforms — routing engines, IVR systems, workforce management integrations, CRM connections — where configuration changes are made continuously as business requirements evolve. A routing rule misconfigured during a peak trading period, a queue priority incorrectly adjusted before a product launch, an IVR flow deployed without validation: in environments processing thousands of customer interactions per hour, these are not minor incidents. They are business-critical failures with immediate revenue and reputational consequences.
High-availability DevOps in these environments requires more than a fast pipeline. It requires a governed pipeline — one where automation enforces process discipline rather than merely accelerating manual steps.
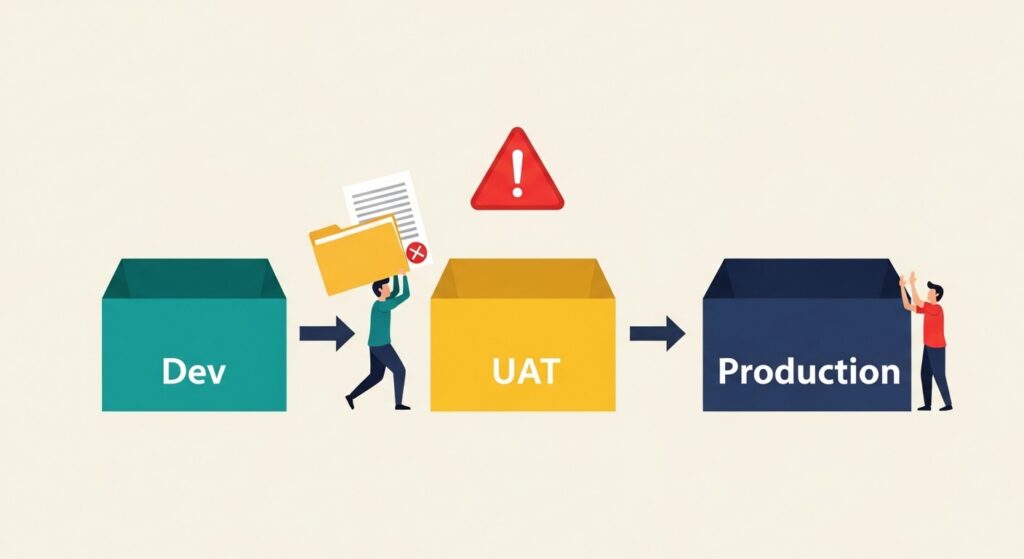
The Hidden Risk in DevOps: Manual Changes & Misconfiguration
Despite investment in DevOps tooling and automation, most enterprises retain significant manual processes at the most dangerous point in the pipeline: the promotion of changes between environments and into production.
The pattern is familiar. Changes are developed in a Dev environment and, once stable, are manually reproduced into a UAT environment for user testing. If testing passes, a change control process sees those changes documented — typically by hand — and eventually the work is manually deployed into the production environment. Every manual step in this chain is an opportunity for a typo, a missed parameter, a misunderstood handoff, or a documentation discrepancy between what was tested and what was deployed.
This creates a genuine engineering dilemma. The instinct when faced with deployment risk is to add more process — more approvals, more checklists, more review stages. But every additional manual process layer also adds engineering overhead, slows deployment velocity, and introduces its own error surface. The law of diminishing returns kicks in quickly: at some point, more manual process produces more risk, not less.
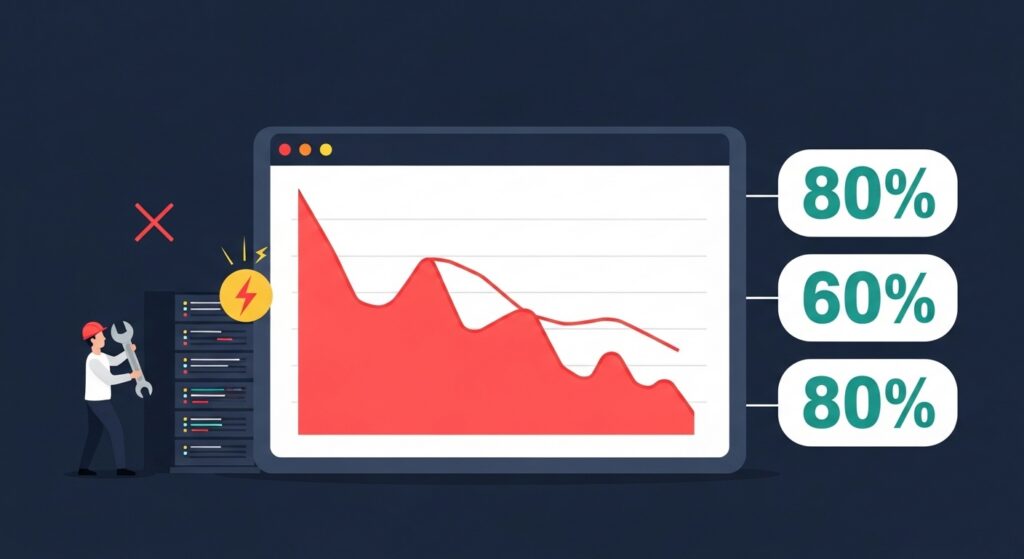
The data reflects this. The IT Process Institute’s Visible Ops Handbook found that 80% of unplanned outages are caused by ill-planned changes made by administrators or developers. The Enterprise Management Association reported that 60% of availability and performance errors result directly from misconfigurations — the incremental, routine changes to environment and system configuration parameters that accumulate across complex platforms. Gartner projected that 80% of outages impacting mission-critical services are attributable to people and process failures, with more than half specifically caused by change, configuration, release, and handoff issues.
The financial consequences follow predictably. Manual configuration errors cost organizations up to $72,000 per hour in application downtime. Application maintenance costs are rising at 20% annually, and 35% of organizations report that at least a quarter of their downtime is directly attributable to configuration errors.
The problem is not that engineers lack skill or diligence. It is that manual environment promotion is structurally error-prone — and no amount of additional manual oversight fully compensates for the absence of automation.
Automating Change Control to Strengthen DevOps Processes
The solution to the manual promotion problem is not more process. It is replacing manual promotion with automated environment promotion — moving changes between Dev, UAT, and production automatically, with validation, documentation, and audit trail generation built into the automation itself.
This is the principle behind changeset-based deployment management. Rather than manually replicating individual configuration changes across environments, a changeset groups related changes into a single, version-controlled, reusable object. That object can be promoted across environments automatically, with each promotion generating the change control documentation that governance and compliance frameworks require — not as a separate manual step, but as a byproduct of the deployment process itself.
The result is faster deployments with less engineering overhead, higher release quality with fewer human-error-driven defects, and a complete, automatically generated audit trail that reflects what was actually deployed rather than what someone intended to deploy. Rollback becomes a controlled, documented operation rather than an emergency manual intervention.
For Genesys Cloud CX environments specifically, this approach addresses one of the most persistent operational risks in the contact center industry: the gap between the change that was developed and tested, and the change that actually reaches the production routing engine. InProd is built around this principle — automating change control, environment promotion, and audit documentation for Genesys Cloud CX configuration so that DevOps teams can move faster without reintroducing the manual error risk that governance processes are designed to prevent.
DevOps Best Practices for Stability and Speed
The following practices characterize mature DevOps processes in enterprise and high-availability environments:
Eliminate manual production edits. Direct changes to production environments — outside of the automated pipeline — are the single greatest source of unplanned outages. No exceptions should exist without a documented, approved, and time-bounded emergency change process.
Automate environment promotion. Changes should move from Dev to UAT to production through automated pipelines, not manual replication. Automation enforces consistency and eliminates the transcription errors that manual promotion inevitably introduces.
Version-control all configuration. Application code, infrastructure definitions, and platform configuration should all be stored in version control systems. If it is not in version control, it cannot be audited, rolled back, or reproduced reliably.
Enforce approval workflows at appropriate gates. Automation should not mean the absence of human judgment — it should mean that human judgment is applied at the right points, with full context, rather than distributed across dozens of manual steps where context is lost.
Monitor continuously and act on signal. Monitoring that does not feed back into the planning cycle is reporting, not observability. Close the loop.
Design for rollback from the start. Every deployment should have a defined, tested rollback procedure. Rollback capability that has never been tested is rollback capability that will fail under pressure.
Track configuration drift. The gap between intended and actual configuration in production is one of the most common and least visible sources of operational instability. Automated drift detection closes this gap.
Standardize release management. Inconsistent release processes across teams and environments multiply risk. Standardization through automation enforces the same quality gates regardless of who initiates a deployment.
Common DevOps Tools Used in Enterprise Pipelines
Enterprise DevOps pipelines typically draw from a consistent set of tool categories:
Version control: Git is the universal standard, with GitHub, GitLab, and Bitbucket as the most widely deployed hosting platforms.
CI/CD platforms: Jenkins remains one of the most widely deployed open-source CI/CD servers. GitLab CI, GitHub Actions, and Azure DevOps provide tightly integrated pipeline capabilities within their respective ecosystems.
Containerization & orchestration: Docker standardizes application packaging across environments. Kubernetes manages container orchestration at scale, enabling consistent deployment and scaling behavior across development, staging, and production.
Infrastructure as Code: Terraform is the dominant multi-cloud IaC tool for infrastructure provisioning. Ansible is widely used for configuration management and application deployment automation.
Cloud platforms: AWS, Azure, and GCP each provide native DevOps toolchains that integrate with the above tools while adding cloud-native services for monitoring, security, and deployment management.
The right tool stack depends on the environment, the team’s existing capabilities, and the specific risk profile of the systems being managed. In mission-critical environments, the selection criteria should include not just feature capability but auditability, rollback support, and integration with existing governance frameworks.
Frequently Asked Questions About DevOps Processes
What are DevOps processes? DevOps processes are the workflows, automation frameworks, and cultural practices that unite software development and IT operations. They govern how changes move from planning through coding, building, testing, releasing, deploying, operating, and monitoring — continuously and with increasing automation at each stage.
What is the DevOps lifecycle? The DevOps lifecycle is the continuous loop of phases that a change passes through from conception to production and back to planning: Plan, Code, Build, Test, Release, Deploy, Operate, and Monitor. It is designed as an infinite loop — production feedback continuously informs the next planning cycle.
What is the difference between continuous integration and continuous delivery? Continuous integration (CI) automates the merging, building, and testing of code changes as they are committed. Continuous delivery (CD) ensures that every successfully integrated build is always in a deployable state, ready for production release. Continuous deployment extends this further by automatically releasing every validated build to production without manual intervention.
How do DevOps processes reduce outages? By replacing manual handoffs with automated pipelines, DevOps processes eliminate the transcription errors, missed steps, and documentation gaps that cause the majority of unplanned outages. Research consistently shows that most production failures are caused by people and process issues — specifically change and configuration errors — rather than technology failures. Automation addresses the root cause directly.
What tools are used in DevOps? Common DevOps tools include Git for version control, Jenkins and GitLab CI for continuous integration, Docker and Kubernetes for containerization and orchestration, Terraform and Ansible for infrastructure as code, and Azure DevOps or AWS CodePipeline for cloud-native pipeline management. In platform-specific environments such as Genesys contact centers, specialized tools for configuration governance and automated environment promotion address the gap between generic DevOps toolchains and mission-critical operational requirements.
DevOps Is Not Just Speed — It’s Controlled Speed
The promise of DevOps is not simply faster releases. It is the ability to move quickly with confidence — knowing that automation enforces the quality and governance standards that manual processes struggle to maintain consistently at scale.
In enterprise and mission-critical environments, this distinction is decisive. The teams that get DevOps right are not the ones who remove all friction from their pipelines. They are the ones who remove the right friction — replacing manual, error-prone steps with automated, auditable, and reversible processes while preserving the human judgment gates that genuinely add value.
That balance between innovation velocity and operational discipline is what separates a mature DevOps process from a fast one. And in environments where a single misconfigured parameter can trigger a six-figure outage, maturity is not optional.